
A Potential AI Bottleneck Multibagger
Microcap investing with exponential potential; when risk meets potential

Hello team,
I have been working a lot on the current AI bottleneck lately - networking and bandwidth, not just because social medias are full of companies in the sector but because many names are showing up on my screeners, which means they are being accumulated and breaking out key levels - which is what we want to buy.
I already talked about GlobalFoundries a few days ago - the SiPho fab leader. We won’t talk about SiPhos today - although we will still talk about networking bottlenecks, but I want to share that I plan to write about Soitec this week, and as the stock is close to a pretty sweet spot and my write up isn’t ready yet, I wanted to share it with you before.
I wanted to share this first so you can start looking around before the full report hits your inbox in the next few days - hopefully.
The AI Networking Bottleneck
We went through the basics in the GlobalFoundries thesis, detailing how optics are the only viable solution to increase bandwidth and decrease latency within AI data centers, currently the #1 focus for compute providers.
As we move from training to inference, the needs change. Training was about sheer data compute, having as much of it as possible to train behaviors. Inference is a different beast; it requires compute but also speed. Data must transition rapidly between network points before being processed. Today, we have the power to process this data; we have so much power that GPUs end up staying idle, waiting for data to reach them.
This is today’s inference issue: the speed at which data transits between compute points, mostly due to the limitations of copper. To use my previous analogy.
Imagine a highway limiting the number of people passing through. Say 2M cars can drive simultaneously. But in the middle, there’s a section where only 1M can pass (bandwidth), controlled by tolls that require travelers to change their car engines (latency and power). That creates waiting time, slowing down the entire system.
The market is excited about photonics because it is the only way to scale compute further. Adding more GPUs today is like adding workers on a construction site waiting for supplies. It won’t build that house faster, what we’d need is to move the supplies faster. But as noted by Jensen and Astera Labs’ management, we are still years away from industrial scale silicon photonics.
The AI factory is the new unit of computing. To connect a million GPUs, we can no longer rely on the old physics of copper. Silicon photonics is now central to the next generation of AI infrastructure.
We have squeezed every last drop out of copper. At 224G per lane, the physics simply demand light. The transition is no longer a choice; it is a thermal necessity.
The technology is ready, but the supply chain is not yet at the ‘Industrial Scale’ required for zero-defect AI factories.
Nvidia GTC keynote
What’s up until then? There might be another way to bridge the gap.
FPGA & SmartNIC
To be clear: these technologies won’t replace the long-term need for photonics, but they are usable today, faster to deploy, would remain useful even after the transition and could help with it, temporarily and in some cases.
Field-Programmable Gate Array (FPGA)
A FPGA isn’t a GPU nor a CPU. Think of it as a Ditto (the Pokémon). By now, we probably all know the difference between those two.
CPUs are the brains, excellent at complex, vertical, serial tasks.
GPUs are the muscles, excellent at horizontal, parallel computing.
Before going further, we need to understand the physical optimizations of GPUs and CPUs. Chips are made of silicon, a semi-conductive “sand” on which electrical paths are etched, physically, to optimize electrical flows between components depending on the final need of the semiconductor. Exactly like we would manufacture a jet to fly as fast as possible for example; you’ll understand easily it isn’t meant to drive. One path, one function, no detour, no waste of energy.

We thought GPUs/CPUs would be enough; they are compute wise but aren’t self-sufficient and hyperscalers are now looking to optimize them, and that requires other hardware; one of them being FPGAs.
FGPAs also are semiconductors, silicon. The difference between GPUs/CPUs and FGPAs is physical. While the first have finite and optimized etched circuits, the second has configurable etched circuits. It has more than it needs but those can be turned on or off, depending on the needs.
Imagine driving in a city. There are plenty of roads, right? A GPUs/CPUs will have only one road, the most efficient one and everyone would follow it. A FGPA on the contrary will have all the roads configured, but traffic lights will force drivers on this or that one, depending on where they are and want to go.
GPUs and CPUs can be optimized like with Nvidia’s CUDA, making the road smaller or bigger, slicker, changing the wheels or the cars to accelerate traffic. But the road itself will always be the same, from one point to another. It cannot be changed because it physically is built that way and you aren’t going to destroy buildings to change the road because Michel wants to pass here and not there. No one cares Michel, follow through and be optimized.
With FGPA, the road Michel wants to take already exists. It is closed but it exists and if the need were to favorize this road, then it could be opened. This kind of reconfiguration isn’t simple nor extremely rapid, but once the configuration is set - which is the hardest part, a simple reboot can transform the same hardware with one optimization, for one function to another one, “just like that”.
Your question now should be: then why do we have GPUs and CPUs?
Well, material optimization remains the best form of optimization. Imagine a car with pals which can turn into an helicopter. A normal car will be smaller, faster, consume less. Sure, you won’t fly with it, but sometimes you just need to go see grandma, not to fly. GPUs and CPUs are much better at what they do.
So the next logical question is… Why would we use those, then?
First, they are already very used in specific sectors nowadays as the ultimate focus of those semiconductors are latency, critical in cybersecurity, defense systems or algorithmic trading for example. But they are starting to become critical for a much bigger market who’s actual bottleneck is both bandwidth and latency: inference.
AI infrastructure investments are shifting from training models to querying the models at scale known as inference. Inference is continuous, distributed, and extremely latency-sensitive.
While training primarily happens via network GPU cards at the core of the data center, inference happens everywhere, continuously, at the edge, in telcos, and in enterprise data centers. This creates massive networking and interconnect bottlenecks, and that’s exactly the problem that Silicom excels in solving.
Liron Eizenman, Silicom Q4-25 Earning Call
Because they are configurable and reprogrammable, they can be used improve network congestions, acting as a GPU/CPU when needed, or a hybrid. They have two key characteristics which make them so valuable.
Modularity: As they are modular, they can treat information differently. A GPU needs a large amount of data before starting its compute and will stay idle until it has enough data - you don’t want million-dollar hardware to stay idle. A FPGA can be configured to compute while data flows. It can be configured to only treat one type of data while being energy optimized. Or it can be overly specialized for a temporary task companies won’t spend thousands to engineer a GPU for.
Interconnectivity: They can be directly interconnected within the hardware - to the GPUs/CPUs or any other chips, which largely improves latency and removes bandwidth bottlenecks as data flows to them directly at electrical speed. Which will brings us to our second subject today.
FPGA can be seen as Dittos used for niche usage, when a GPU or a CPU won’t be as efficient of isn’t worth being developed for, in very specific use case where nothing else can optimize workflows or for very specific needs.
SmartNICs
The FPGA is the silicon, it isn’t complete by itself; it needs to be included within a motherboard with potentially other components (RAM or/and DPUs) and connectors to fit within the system. The final product is called SmartNIC, a Ditto board focused on networking, optimizing packet flow between the network and components with the lowest latency possible.

FPGAs and SmartNICs are usually used in modular environments where latency has to be the lowest possible: Cybersecurity, 5G networks, virtualization, defense systems, algorithmic trading… And now, potentially inference, connected to GPUs, CPUs, or any hardware within the racks with limited copper in between.
A Ditto which can be connected to critical infrastructure, optimized for low latency and maximum bandwidth.
Silicom LTD.
This is the company we’ll look at today, a pure SmartNIC player. Silicom doesn’t do FPGAs; they buy them and manufacture SmartNICs for their clients. Which also means they do not own tech IPs and are just a component assembler at the end of the day, not the highest value in the chain but still selling a very demanded finished product.
The company and sector have been a bit distant from the AI revolution; there were always FPGAs in quantity in AI datacenters but the need for customized ones wasn’t there then, and it might be now. Might be.
Let’s talk about the environment first.
Nvidia, AMD & Co.
All the big guys already have FPGAs; as I said, it isn’t new. AMD bought a company called Xilinx in 2022, was known as the go-to for FPGAs and today’s leader in the sector. Intel acquired Altera in 2015 but didn’t do great with it and partially sold it this year, while Nvidia is focused on SmartNICs with ASICs, not FPGAs, via BlueField.
Those are for the big integrated guys, but there also exist some independent names manufacturing FPGAs: Lattice and Microchip - two stocks with a pretty crystal-clear growth trend at the moment.

And there is a crystal clear source for actual demand: AI.
And this companion role becomes foundational as AI workloads push system-level complexity higher and higher and drive to faster time to market, as AI servers disaggregate into processor boards, networking cards, security cards, power and cooling modules, storage, and other specialized blades. FPGAs show up everywhere in the data center. We are also seeing the same trend accelerating in physical AI. Intelligence is moving closer to the sensors where data is created. A single robot can have multiple vision sensors, including image, LIDAR, radar, and infrared, requiring fusion, aggregation, and preprocessing.
In addition, humanoid robots could have dozens of motors, requiring high precision and low latency control. Companion chip FPGAs sit, besides those sensors and actuators, to synchronize high-bandwidth vision streams with real-time motion and deliver deterministic responses.
Lattice Semiconductor Q4-25 Earning Call
Two stocks which could be considered, but their risk profiles aren’t comparable to Silicom, with 8x and 24x sales and large competition from Intel and AMD. No, my focus wouldn’t be on FPGAs because those are only one part of the story, the critical part, but only one part.
The key for today’s networking bottleneck is flexibility. Hyperscalers have very specific needs which require independence, something that today’s leaders do not have.
AMD and Nvidia both have closed ecosystem and will not propose customized hardware with manufacturers they do not partner with. They propose a finished product which is enough in 95% of cases but the last years showed that hyperscalers needed independence and further customization, not for the bulk of their compute but for the optimized niche.
And this is what Silicom proposes. They are a middle man, constructor agnostic, and can meet any kind of optimized hardware demand for any kind of niche.
The Thesis
To recap the thesis clearly: FPGAs are already used in AI datacenter and should only increase in usage as the need for flexibility and network optimization grows. The question is how will those be integrated and why would Silicom benefit?
The first answer is that demand will continue in their core vertical - very low latency services which now also leverage AI like cybersecurity, algorithmic trading and the others we already talked about. Demand on those sector is accelerating as confirmed by management.
Just to give an example, a few weeks ago, we announced that the global networking and security as a service leader significantly expanded its deployment of Silicom Edge devices into multiple additional use cases, increasing our expected annual revenues from this customer from $3 million-$4 million to between $8 million and $10 million, more than doubled, with some of those incremental revenues expected in the coming months.
Q4 revenues grew 17% year-over-year to $16.9 million, well ahead of our guidance range between $15 million and $16 million. It confirms that the demand for our core product is high, resilient, and strengthening.
Liron Eizenman,
This is step one, the base case. Step two is about the bull case: customized SmartNICs to optimize network bandwidth and latency within inference. Not for special sectors, but for inference itself.
Management was contacted by some hyperscalers not for a definite order, but for a POC - Proof of Concept. There is interest in the technology for a larger usage, enough to see if their product can answer the demand to resolve those bottlenecks.
We already have initial orders for our inference-optimized FPGA-based solution to be utilized by our customer at a POC with a hyperscaler end user, and we are developing a dedicated AI NIC based on a leading high-performance networking chip for another AI inference leader. We have initial orders in hand and follow-on POCs underway. We are also engaging with multiple customers, and we are in advanced discussions with additional AI inference chip vendors.
Liron Eizenman, Silicom Q4-25 Earning Call
This isn’t a thesis coming from my imaginary mind; it is real demand coming from hyperscalers to try out SmartNICs and see if they can help resolve actual bottlenecks, combined with real demand for their product in their known verticals.
In 2025, we achieved eight major new design wins across edge systems, SmartNIC, and FPGA solutions, with both new customers and existing Tier 1 customers expanding their engagements with us. Those design wins give us strong visibility into 2026 and beyond, supporting our expectations for double-digit revenue growth for the year ahead.
We are again targeting between 7 and 9 design wins in the current year, spanning across all our product lines.
Liron Eizenman, Silicom Q4-25 Earning Call
Now, keeping feet on the ground, those are what they are: POCs. They might not be conclusive and won’t yield massive revenues this year.
And even for 2026 as a whole, I think we are not expecting them to be still huge. There is an opportunity for that, but we definitely are expecting our core business to be very, very strong in 2026 and keep growing. And each of those opportunities, it can boom at any point in time, but right now, we’re still in the early stages. But we feel that we are very strong in the early stages and that we feel very strong traction on each of those.
Liron Eizenman, Silicom Q4-25 Earning Call
But the bull case doesn’t rely on massive revenue tomorrow, it relies on the potential for SmartNIC to be valuable within inference, for hyperscalers, to help with the actual bottlenecks - releasing pressure on the network and improving GPU usage, reducing idle time, etc...
Still feet on the ground, we aren’t talking about redefining inference neither, simply helping on key pressure points. If the opportunity was as huge as the new GPUs, hyperscalers wouldn’t do a POC with such a small company, they’d either develop it internally or buy the company. Working with an assembler makes sense if the need is large enough to justify the spending, but small enough not to do it internally.
The potential is real. The interest is real. The POC is real. But the opportunity is niche. That being said, “niche” at the scale of hyperscalers spending hundreds of billions per year is the Everest from the point of view of a ~$100M company.
So the inference happens everywhere. And when we say everywhere, it could be at the edge of the network, it could be a local data center, it could be a telco data center, it could be even in the enterprise. And there are so many different installation types and deployment types and types of different networking they need to support, then different cards, different companies developing different inference chips, not all of them able to provide all the different layers that they need to cope with. So they will only focus on the inference chip, but they need someone to complement it on the networking side. So if you want to do, as you said, scale out to multiple servers, multiple ports, how do you do it efficiently? How are you making sure that the network is not a bottleneck and that you actually get the most that you can out of the inference chip? That, I think, is the key. And there’s no like it’s very fragmented and very different from deployment type to another. That’s where the opportunity is created.
Liron Eizenman, Silicom Q4-25 Earning Call
If those POCs were conclusive, we’d pass from niche hardware for low-latency verticals returning to double digit growth to an hyperscaler partner with a feet in the AI inference game optimization sector. This certainly would trigger market’s rerating.
Financial Profile & Risk
To state this clearly: we are looking at a micro cap. A ~$100M capitalization, very small, very volatile and very risky - although I’ll mitigate that risk right away.
Silicom is a ~$100M cap with ~$50M of cash and equivalents in the bank for no debt. This is what we call a fortress and leaves management with many opportunities, from acquisition to investment into manufacturing capacities or buybacks - which are the preferred use for now. And management confirmed the actual demand for their products do not require much capacity expansions or R&D.
So in some of those projects, as we said, we’re leveraging existing IP and we’re leveraging existing know-how. So it’s not like we’re starting from scratch. So for some of those opportunities, it’s actually taking some of our existing products, making some changes on them so we can react very, very fast, and it can actually be a quick road to revenue here and quick road to design wins. On some of the others, we do need to do some development, but we already started with that. So we are deep into the development of some of those. So we think overall, we are expecting it to be faster than what we’ve seen in the past.
Liron Eizenman, Silicom Q4-25 Earning Call
That said, they have the cash needed if need be to accelerate production, expand, or anything else. We are talking about a company trading at 1x EV/sales with no real need for its cash - yet, but buybacks and safety cushion.

Although this safety cushion is necessary as the company remains unprofitable. We’re talking about ~30% gross margins for -20% operating margins and a loss of ~$3M per quarter. As shared earlier, Silicom is an assembler and do not own IPs or patents, which means lower margins and at the moment, no profits. So cash is important for the company.
Profitability isn’t the bull case either way here, we are with a small cap growth name and returns will be tied to demand, growth and hyperscalers POCs. But at today’s valuation, with double digit growth guidance and a very large cash cushion, risk always exists but it seems much lower than many other micro cap.
Investment Plan
As for investing, micro cap always come with their risk and volatility so always keep this in mind. This is a risky investment. Based on a clear thesis but risky nonetheless.
A company trading at 1.7x sales, less than 1x EV/S with ~50% of its capitalization in cash, a very healthy guidance of double-digit growth for its core business without including a potential tailwind from the actual largest AI bottleneck, which means growth could be much stronger if the POCs were to be conclusive.
The last time the company traded at double-digit growth, it was trading at ~3x sales and this growth is today’s guidance only based on core business.

If we were to combine a 15% FY26 growth with a 3x sales multiple, which would be the base case, without a hyperscaler POC success, we’d be looking at a ~$200M cap, ~100% higher than today. An hyperscaler POC success would justify a higher growth rate and multiple, which I wouldn’t try to model but would push the name higher.
The way I see this name is a good risk-reward with excellent potential return in the base case, and exponential returns in the bull case - public acknowledgment that their SmartNIC has value in hyperscaler AI inference systems. The market would anticipate this and won’t wait for orders to pour in to reward the stock; any positive announcement in favor of their hardware will trigger demand directly, in anticipation of future growth. Narrative will be key on this name.
I already have a position as price action confirmed demand for this stock, which probably means others share my thesis.
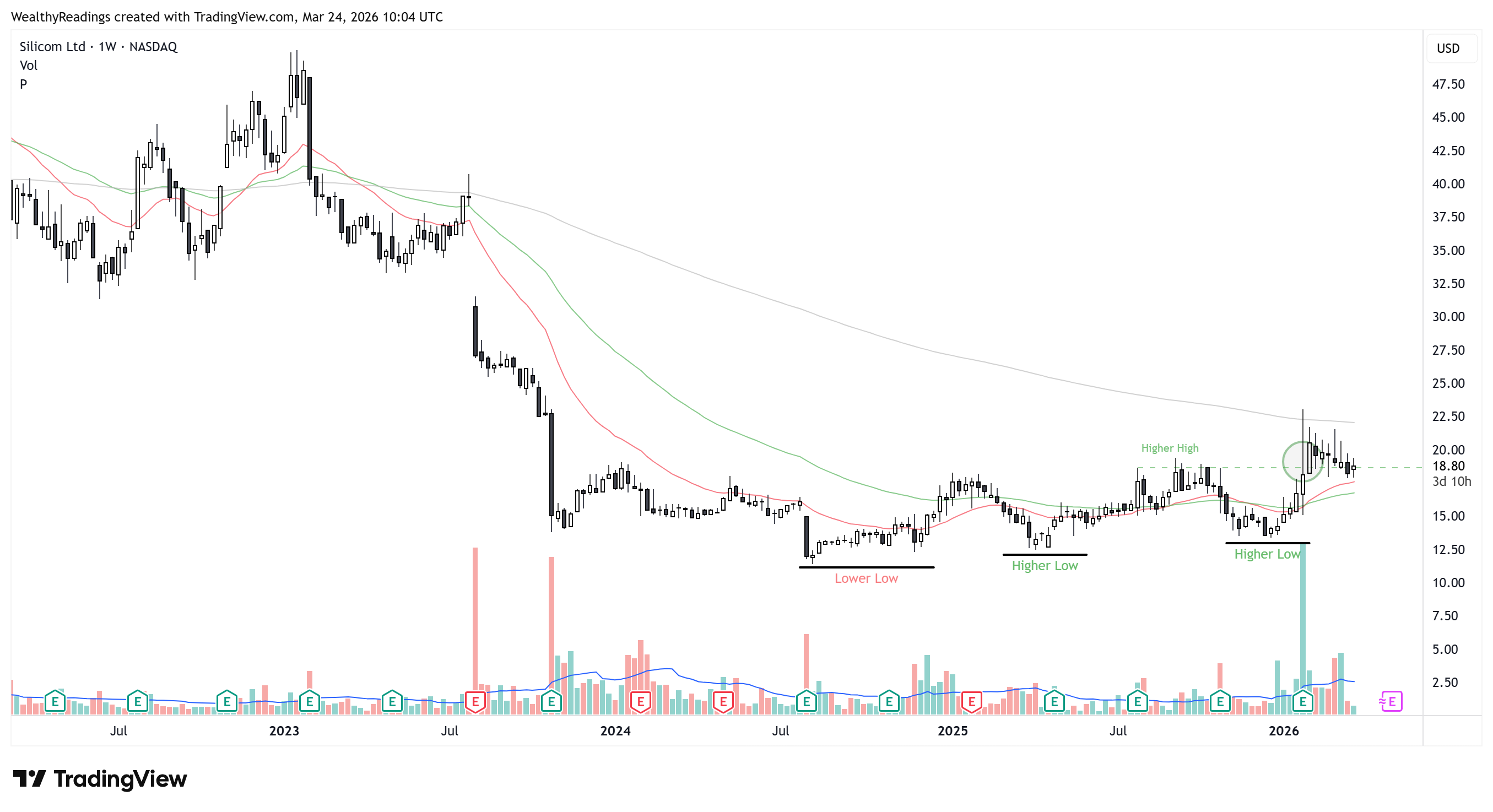
The base and the bottom are clear and were fixed before the hyperscaler and AI potential, which is a good sign as buyers did not have today’s expectations. The breakout happened last quarter when these announcements were made, meaning the market accumulated the return of core growth and got excited by the AI potential.
Clear base, clear volume increase, clear breakout, clear retest.
This is growth investing 101; this is the very beginning of this stock’s potential, while the downside risk is still minimum. Any negative news on the hyperscaler POC would certainly trigger selling, but at less than 1x EV/S and with ongoing buybacks, I wouldn’t expect a -50% overnight - although once again this is a micro cap.
This is a high risk, high reward name with the risk being diluted by a strong core business, massive cash and low valuation. But we are still talking about a $100M capitalization within a very volatile environment and sector. So it is important to be cautious with those speculative names.
The potential is here, demand for the stock as well. Now let’s follow the core business and the hyperscalers POCs.
Disclaimer: I am not a licensed financial advisor, analyst, or broker. This content reflects my personal opinions and investment decisions for informational and educational purposes only. I hold positions in securities discussed and may buy or sell without notice. Nothing here constitutes a recommendation to buy, sell, or hold any security. Past performance does not guarantee future results.
Always conduct your own research and consult a qualified professional before making investment decisions. I accept no responsibility for any financial losses.
great write up - have you started a position in SILC?
Thank you for the fantastic insight on this, really well written!
I am considering deploying capital here after seeing the POC order today. Wanna hear your thoughts on their margins trajectory. These guys only assemble so would make sense that their margins would not be lucrative, do you see that impacting the valuation? Also, does the fact that they could get competition soon make you rethink this (either from hyperscalers themselves or any company), or is the TAM too big to be bothered about this? Thank you again for the article